
2 min read.


Hace 5 años la ciencia computacional estaba en medio de una revolución tecnológica, por primera vez en la historia pudieron diferenciar entre fotos de gatos y perros, esto no suena como un gran problema, los humanos lo hacemos casi sin pensar, pero los humanos hemos tenido millones de años para evolucionar nuestro sistema visual, de hecho si gozas de una vista promedio, utilizas cerca del 50% de la corteza cerebral solamente para procesar datos visuales.
Ya hemos hablando previamente en el blog respecto a la revolución tecnológica de la A.I en campos como la medicina, sin embargo en el problema de detección de objetos buscamos encontrar a cada elemento individual que se encuentra en la escena, descubrir dónde están sus coordenadas y qué son.
Este es un gran reto para las computadoras y algo en lo que los investigadores llevan trabajando más de 50 años, en esta gran revolución tecnológica se creó un nuevo modelo estadístico: las Redes Neuronales Convolucionales, que están diseñadas para imitar el sistema visual humano, en lugar de describirle a la computadora exactamente como se ve un gato y como se ve un perro, le damos muchas imágenes de gatos y perros y dejamos que aprenda por sí misma, las redes neuronales construyen un modelo estadístico que aprende a asociar patrones e imágenes con la etiqueta correcta (perro o gato).
Los clasificadores modernos reconocen miles de animales, objetos y escenas diferentes.
También se pueden utilizar estos algoritmos en personas para descubrir su identidad, su estado de animo, su edad, su genero, etc.
Tal vez la mejora más importante en el campo es que con los modelos anteriores, una computadora tardaba 20 segundos o más procesar una sola imagen, ahora con los algoritmos más avanzados, se pude procesar una imagen en solamente 20 mili segundos, esto permite la detección de objetos en tiempo real y con esto una infinidad de aplicaciones como:
- Ayudar a débiles visuales a navegar el mundo.
- Vehículos que se manejan solos.
- Minimizar drásticamente los accidentes de transito.
- Detectar células cancerígenas.
- Rastrear animales en peligro de extinción.
- Controlar robots sumergibles que navegan las aguas más profundas.
Todo esto es posible porque muchos códigos y modelos, como YOLO creado por Joseph Redmon, son open source y de dominio público, gratis para que todos los estudiemos y utilicemos. Gracias a la disponibilidad de esos recursos el crecimiento del campo es exponencial.

YOLO:
You Only Look Once (YOLO) representa el estado del arte en cuanto a tecnología de detección de objetos.
Cabe mencionar que la clasificación y la detección son problemas diferentes, la clasificación se refiere a la determinación de la clase de objeto (¿Qué es?), la detección busca identificar las coordenadas de objetos individuales en el espacio (¿Dónde está?, ¿Cuántos son?, ¿Cuánto mide?).
Los sistemas de detección pasados reutilizaban clasificadores o localizadores para realizar detecciones, aplicaban el modelo a una imagen en múltiples zonas y escalas, las regiones con mayor puntaje se consideraban detecciones, aquí es donde YOLO es revolucionario, aplica una sola red neuronal a la imagen completa (you only look once), esta red divide en regiones y predice recuadros delimitadores y probabilidades para cada región, estos recuadros son después ponderados con las probabilidades obtenidas, así es como YOLO puede clasificar y detectar objetos en una sola pasada por la red, en lugar de cientos o miles como se usaba antes de las redes neuronales convolucionales.
Demostración de YOLO:
Utilizando una GPU (Graphics Processing Unit) Titan X con 12 GB de memoria GDDR5X, YOLO puede detectar decenas de objetos en tiempo real a 30 cuadros por segundo, esto ha permitido un avance enorme en el campo de la detección de objetos.
Para entrenar la red neuronal utilicé una GPU GTX 1060 con 6 GB de memoria GDDR5/X, con este poderoso componente se obtuvo un entrenamiento aceptable en solo 8 horas.
El objeto que elegí es una mascota de la oficina: “Gizmo” ya que debía ser un objeto que fuera nuevo para YOLO, cosa difícil considerando que continuamente “aprende” nuevas clases de objetos.
 Él es Gizmo
Él es Gizmo
Es importante que el data set con las fotos del objeto sea de mas de 2,000 fotos y contenga variaciones en la posición, iluminación, orientación y escala.
Igualmente es necesario configurar YOLO para nuestra infraestructura y para nuestro caso específico (Gizmo), terminado este proceso podemos dejar a la GPU hacer lo que mejor sabe y esperar los resultados que arroja después de ciertas iteraciones.
En las siguientes imágenes podremos ver el proceso de aprendizaje de YOLO, cada iteración disminuye el error y se acerca más a la respuesta que daría un humano.
Así luce el entrenamiento de YOLO
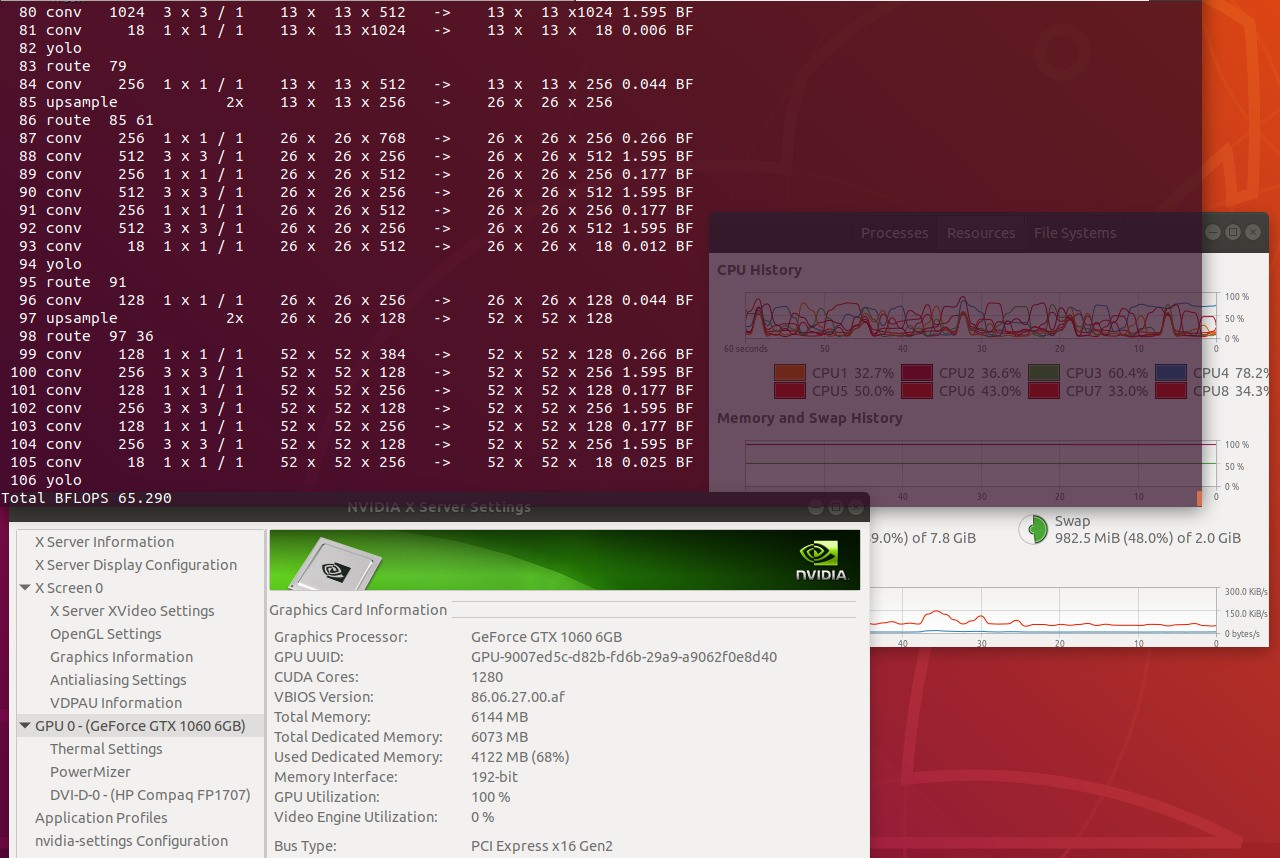
La información después de cada iteración, en este caso la 2622 donde ha analizado 167,808 imágenes:
.png?width=751&name=MicrosoftTeams-image%20(1).png)
Aprendizaje:

Predicción que hizo YOLO con los datos obtenidos después de 500 iteraciones, tiene una idea de donde esta el objeto y cree con 28% de certeza que es un Gizmo, no es suficiente pero es un buen inicio.

100 iteraciones después (2.5 min.) en la iteración 600, podemos distinguir que la altura aumento y se acorto a lo largo, el entrenamiento está funcionando.

En la iteración 2,000 podemos ver un avance mucho más notable, el recuadro aun no es perfecto pero empieza a ser aceptable para aplicaciones reales, han pasado solo 8 horas desde que inicio el entrenamiento.

Cerca de las 8,000 iteraciones tenemos resultados casi perfectos, donde tiene 100% de certeza de que encontró un Gizmo.


Para el entrenamiento únicamente incluí 1000 fotos del Gizmo de la oficina, con baja resolución y tomadas con la cámara web de mi laptop, es impresionante como incluso con estas desventajas la red es capaz de reconocer Gizmos diferentes que nunca ha visto, al original de la película lo reconoce desde las 2,000 iteracciones.
Referencias:
- Joseph Redmon, Ali Farhadi. YOLOv3: An Incremental Improvement
- University of Washington, arXiv:1804.02767, 2018
- Fork de YOLOv3 con bug fixes y optimizaciones: https://github.com/AlexeyAB
- Página web de YOLO/Darknet https://pjreddie.com/darknet/yolo/
- Ted Talks de Joseph Redmon: https://www.ted.com/talks/joseph_redmon_how_a_computer_learns_to_recognize_objects_instantly?language=es

