3 min read.
.png?width=50&name=MicrosoftTeams-image%20(86).png)

En los últimos años el Big Data ha tomado gran fuerza al punto en el que podemos asegurar que en el día a día el concepto “Data Lake” no nos resulta ajeno, sin embargo, es posible que su funcionalidad en la industria no quede del todo clara.
Por un momento imaginemos que se tiene una nula interacción con el cloud y lo que hemos visto es el sistema tradicional de almacén de datos en instalaciones físicas, que es una tecnología bien establecida, pero que es compleja de diseñar, de construir, de escalar y forzosamente requiere de datos estructurados, teniendo vinculadas nuestras capacidades de computación.
Y ahora bien, dado que tenemos un número inmenso de jobs que analizan grandes conjuntos de datos, cuando decidimos construir un almacenamiento de datos out-of-line, nuestras principales preocupaciones serán los costes de almacenamiento y el rendimiento en lecturas. Sin embargo, dentro del modelo de cloud esto no será un problema.
Todos los proveedores de cloud computing tienen una oferta de servicios de almacenamiento de objetos de bajo coste, por ejemplo Simple Storage Service S3 en AWS, que se convierten en una opción directa para servir como capa cruda para alojar los datos desde el nivel operativo, ya sean estructurados o no estructurados.
“Es un repositorio centralizado que te permite almacenar todos tus datos estructurados y no estructurados a cualquier escala.”
— Data Lake definición por AWS

Los datos corporativos
Hoy en día, todas las compañías generan una cantidad masiva de datos y sin embargo, en su mayoría no recopilan esta información; perdiendo la oportunidad de aprovechar los beneficios de estos datos crudos para convertirse en ideas para llevarnos al siguiente nivel.
El análisis de datos en tu negocio puede reflejarse en increíbles resultados como:
- Reducir costos operativos
- Aumentar áreas de oportunidad
- Responder a la demanda de nuestro clientes en tiempo real, apoyados de M.L. para tomar una postura predictiva y no reactiva.
Data Lake es un enfoque de infraestructura para romper silos de datos, centralizándolos en un núcleo y se utiliza para potenciar el análisis de datos, la ciencia de datos y las cargas de trabajo de aprendizaje automático.
Además, se complementa un almacenamiento de datos ya existente, siendo una fuente de datos estructurados y no estructurados. Y sabiendo, que la nula gestión de nuestros datos podría terminar como un Data Swamp, que es un lago de datos afectado e inaccesible para los usuarios que cuenta con poco valor.

Arquitectura de la solución Data Lake en AWS
En el punto medio de nuestra infraestructura se centra un S3 Bucket: servicio de almacenamiento de alta disponibilidad y rentabilidad. Acompañado por un catálogo de servicios utilizados para la ingestión de datos, categorización y búsqueda hasta de procesamiento y analítica; todo esto bajo altos estándares de seguridad y gobernanza por parte de AWS.
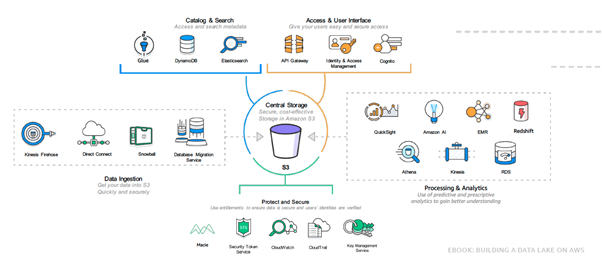
En este diagrama, observamos una infraestructura completa de la cual no existe limitación en la construcción de nuestro data lake, posibilitando la integración de servicios como AWS Lambda para generar una infraestructura serverless o bien incorporar aplicaciones ETL (Extracción-Transformación-Carga) con ejecución en EC2 o ECS.
Por esta versatilidad, mencionaremos los diversos servicios utilizados dentro de un data lake:
Data Ingestion.
- Kinesis Data Streams
- Kinesis Data Firehose
Data Management.
- AWS Glue
- AWS Athena
- Amazon DynamoDB
- Amazon ElasticSearch
Data Analysis.
- Amazon Redshift
- Kinesis Data Analytics
Lake Formation
En AWS re: invent 2018, AWS ha anunciado Lake Formation, un servicio de lago de datos integrado con una "consola central" que facilita la ingesta, la limpieza, el catálogo, la transformación y la seguridad de los datos; y los pone a disposición para el análisis y el aprendizaje automático utilizando múltiples servicios subyacentes de AWS.
"Crear un lago de datos con Lake Formation es tan simple como definir el origen de los datos y qué políticas de seguridad y acceso desea aplicar. Con este servicio, se recopilan y catalogan los datos de bases de datos y almacenamiento de objetos, se trasladan al nuevo lago de datos de Amazon S3, se limpian y clasifican mediante algoritmos de aprendizaje automático, para aportar seguridad al acceso de toda información confidencial."
Fuente: AWS Lake Formation

En resumidas cuentas, al conocer un poco del enorme potencial dentro de un Data Lake, podemos entender la ventaja que ofrece AWS. Ahora sabemos que todas las organizaciones pueden sacar provecho de esto mediante una correcta guía de implementación, e inclusive es posible integrar un ambiente multi-cloud.
Somos expertos certificados en AWS ¡Contáctanos para asesorarte!
 ¡Conoce más artículos en nuestro blog!
¡Conoce más artículos en nuestro blog!